Best AI Models You Can Run on Your Phone Offline in 2026: Gemma 4, Llama 3.2, Dolphin & More
A practical guide to running Gemma 4, Llama 3.2, Qwen 2.5, Phi-4, Dolphin, and uncensored AI models on your phone with no internet. Includes RAM requirements, model sizes, and what each model is best at.

Two years ago, running a large language model on a phone was a novelty. In 2026, it's practical. Models like Google's Gemma 4, Meta's Llama 3.2, Microsoft's Phi-4, and community-driven models like Dolphin and Hermes run at usable speeds on the phones most people already carry.
This guide covers every model you can run on your phone today through HAVEN, what each model is best at, how much RAM and storage you need, and why some of these models matter specifically for survival and emergency preparedness.
How On-Device AI Works
Cloud AI (ChatGPT, Claude, Gemini) runs on remote servers. You send your question over the internet, the server processes it, and sends back an answer. On-device AI runs the entire model locally on your phone's processor. No internet. No server. No data leaves your device.
The format that makes this possible is GGUF (GPT-Generated Unified Format), created by the llama.cpp project. GGUF files contain quantized model weights that are optimized for CPU inference on consumer hardware. A model quantized to Q4_K_M (4-bit precision with mixed quantization) typically runs 3-5x smaller than the original while retaining most of its intelligence.
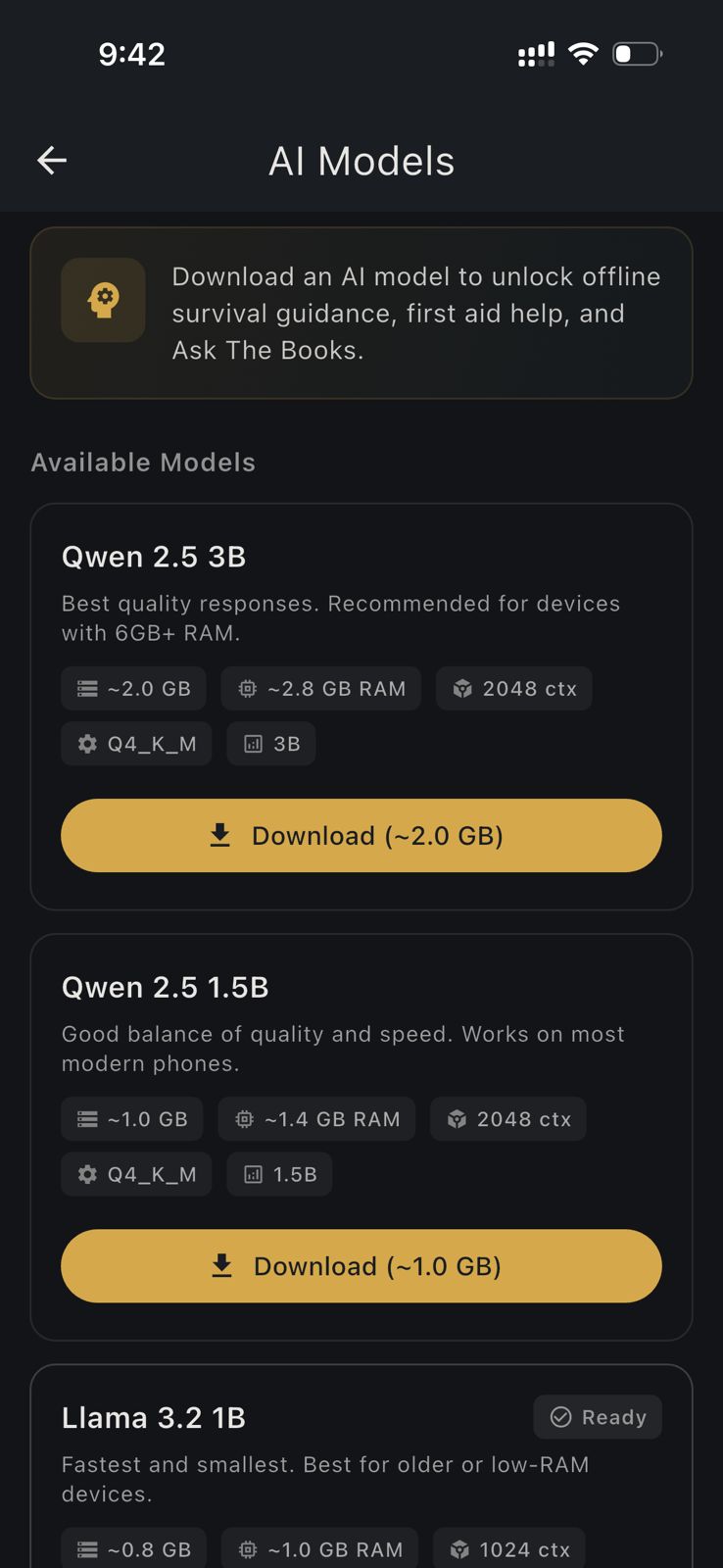
HAVEN curates 19 GGUF models and lets Pro users import any additional GGUF from Hugging Face or other sources.
Gemma 4: Google's Vision AI on Your Phone
Gemma 4 is the headline model in 2026 for mobile AI. It's Google's latest open-weight model, and it's the first practical multimodal model (text + vision) that runs on a phone.
Gemma 4 E2B Instruct
- Parameters: 2.3B active (5.1B total with expert routing)
- Download: ~1.3 GB + 200 MB vision projector
- RAM needed: 10 GB+ (vision processing requires significant memory beyond the model file size; 8 GB devices don't have enough headroom)
- Best for: Environment Scan, general chat, quick visual analysis
Gemma 4 E4B Instruct
- Parameters: 4.5B active (8B total)
- Download: ~2.5 GB + 200 MB vision projector
- RAM needed: 12 GB+
- Best for: Higher-quality Environment Scan, detailed terrain analysis, complex survival questions
What Makes Gemma 4 Special
Gemma 4 includes a vision projector, a specialized neural network component that translates image data into the same representation space the language model uses. The projector adds significant memory overhead, which is why vision models need more RAM than their download size suggests. On devices with 8 GB or less, the OS, the app, the model weights, and the projector compete for memory and the model fails to load.
On 10 GB+ devices (E2B) and 12 GB+ devices (E4B), Gemma 4 runs reliably. It doesn't just "see" pixels. It understands scenes: terrain types, structural hazards, water sources, vegetation patterns, weather indicators.
In HAVEN, Gemma 4 powers Environment Scan: point your camera at any terrain and get a survival-focused analysis of hazards, shelter opportunities, water sources, and priorities. Your photo never leaves your phone.
For people searching "how to run Gemma 4 on my phone": you need a device with at least 10 GB of RAM (most 2025-2026 flagship phones). Download HAVEN, upgrade to Pro, and download Gemma 4 E2B or E4B from the AI Models section. No terminal, no Python, no llama.cpp compilation.
Llama 3.2: Meta's Compact Workhorses
Meta's Llama 3.2 models are the most popular on-device LLMs for good reason: they're fast, well-rounded, and available in sizes that fit any device.
Llama 3.2 1B
- Download: ~768 MB
- RAM needed: 4 GB+
- Best for: Older devices, fast responses, basic survival Q&A
The 1B model is HAVEN's recommendation for budget phones and older devices. It won't win any benchmarks, but it answers survival questions competently and responds quickly.
Llama 3.2 3B
- Download: ~1.9 GB
- RAM needed: 6 GB+
- Best for: General-purpose survival assistant, detailed first aid guidance, multi-step instructions
The 3B model is the sweet spot for most users. Noticeably better reasoning than 1B, and it handles complex multi-step survival instructions well.
Qwen 2.5: The Multilingual Option
Alibaba's Qwen 2.5 models stand out for multilingual performance. If you need survival AI in Chinese, Arabic, Spanish, Japanese, Korean, or other non-English languages, Qwen is the strongest choice.
Qwen 2.5 1.5B
- Download: ~1 GB
- RAM needed: 4-6 GB
- Best for: Multilingual users, balanced quality and speed
Qwen 2.5 3B
- Download: ~2 GB
- RAM needed: 6 GB+
- Best for: Best multilingual performance in a mid-size model
HAVEN's UI supports 16 languages, and pairing that with a multilingual model like Qwen means the AI chat itself can respond naturally in your language.
Phi-4 Mini: Microsoft's Reasoning Specialist
Phi-4 Mini Instruct
- Download: ~2.3 GB
- RAM needed: 6-8 GB
- Best for: Math, logic, structured reasoning, nuclear calculations, resource planning
Microsoft's Phi-4 Mini punches above its weight in reasoning tasks. For survival scenarios that involve calculations (radiation exposure windows, water purification ratios, supply duration planning, caloric needs), Phi-4 Mini tends to outperform similarly-sized models.
Ministral 3: Mistral's Instruction Follower
Ministral 3 3B Instruct
- Download: ~2 GB
- RAM needed: 6 GB+
- Best for: Following complex multi-step instructions precisely
Mistral's compact model excels at following detailed instructions without drifting. Useful for step-by-step medical procedures, shelter construction sequences, and multi-phase evacuation plans.
Dolphin: The Uncensored Survival AI
This is where things get serious for the survival community. Standard consumer AI models are safety-tuned to refuse categories of questions. In everyday use, that's fine. In a survival situation, a model that won't tell you how to treat a wound, build a weapon for hunting, or improvise a chemical water treatment is a liability.
Dolphin 3.0, Llama 3.2 1B
- Download: ~770 MB
- RAM needed: 4 GB+
- Best for: Compact, low-refusal model that runs on nearly any phone, including older and budget devices
Dolphin 3.0, Llama 3.2 3B
- Download: ~1.9 GB
- RAM needed: 6 GB+ (~2.7 GB loaded into memory)
- Best for: Mid-range device with fewer content restrictions. Noticeably better quality than the 1B variant.
Dolphin 2.9.4, Llama 3.1 8B
- Download: ~4.6 GB
- RAM needed: 8 GB+ (~8 GB loaded into memory)
- Best for: Full uncensored-style model. Comprehensive survival answers without refusal on any topic. Needs a flagship or recent high-end device.
Dolphin models are built by Eric Hartford and the Cognitive Computations community. They're fine-tuned versions of base models with alignment training removed or minimized. The result is an AI that answers any survival-related question directly: weapons construction, chemical processes, tactical scenarios, field medicine, and more.
The key advantage is that tactical engineering models aren't just for high-end devices. Dolphin 1B runs on a 4 GB phone just as easily as TinyLlama does, giving even budget-device users access to unrestricted survival AI.
In HAVEN, all Dolphin, abliterated, and Hermes models appear under the Tactical Engineering filter.
Llama 3.1 8B Abliterated: Safety Layers Removed
Llama 3.1 8B Instruct (Abliterated)
- Download: ~4.6 GB
- RAM needed: 8 GB+
- Best for: Meta's Llama with safety fine-tuning surgically removed
"Abliteration" is a technique that identifies and removes the specific neural network directions responsible for refusal behavior, without retraining the model. The result is a model with all of Llama 3.1 8B's knowledge and reasoning ability, but without the tendency to refuse topics.
For survival users, this means direct answers about improvised medical procedures, defensive tactics, chemical applications, and other topics that standard Llama would decline. The model's core intelligence is preserved; only the refusal mechanism is removed.
Hermes 3: Advanced Instruction Following
Hermes 3, Llama 3.1 8B
- Download: ~4.6 GB
- RAM needed: 8 GB+
- Best for: Complex multi-turn conversations, creative problem-solving, scenario planning
Hermes 3 is built by Nous Research. It's fine-tuned for advanced instruction-following, multi-turn conversations, and creative problem-solving. It handles complex scenario planning ("I'm in a forest with these specific resources, it's winter, and I need to travel 20 miles to reach safety, plan my next 48 hours") better than most models at this size.
Gemma 3 12B: Desktop-Class AI on Your Phone
Gemma 3 12B Instruct
- Download: ~6.8 GB
- RAM needed: 12 GB+
- Best for: The highest quality responses available on-device. Complex reasoning, detailed medical guidance, nuanced scenario analysis.
This is the largest model in HAVEN's curated list. If your device can run it (typically flagship phones from 2025-2026 with 12-16 GB RAM), the quality difference is dramatic. Responses are more detailed, more accurate, and more nuanced than anything smaller.
Quick Reference: Which Model for Your Device
| Your Device RAM | Best General Model | Best Vision Model | Best Tactical Engineering Model |
|---|---|---|---|
| 4 GB | Llama 3.2 1B | Not supported | Dolphin 1B (~770 MB) |
| 6 GB | Qwen 2.5 3B or Phi-4 Mini | Not supported | Dolphin 3B (~1.9 GB) |
| 8 GB | Gemma 3 4B | Not supported | Dolphin 8B / Abliterated 8B / Hermes 3 |
| 10 GB+ | Gemma 3 4B | Gemma 4 E2B | Dolphin 8B / Abliterated 8B / Hermes 3 |
| 12 GB+ | Gemma 3 12B | Gemma 4 E4B | Dolphin 8B / Abliterated 8B / Hermes 3 |
Related guides
- offline AI chatbot models for phone use
- private offline AI models for phone
- off-grid AI phone setup guide
How to Get Started
1. Download HAVEN free from the App Store or Google Play
2. Upgrade to Pro ($24.99 one-time) for access to all models and features
3. Open AI Models in settings and download the model that fits your device
4. Start chatting with your offline AI, or use Environment Scan with Gemma 4
You can download multiple models and switch between them. Use a compact model for quick questions, Gemma 4 for visual analysis, and a tactical engineering model when you need unrestricted answers.
Every model runs completely offline after download. No internet. No cloud. No data collection. Your survival questions stay between you and your phone.
Ready to get prepared?
Download HAVEN free and start your preparedness journey today.